今天给大家推荐一篇前不久被第42届 IEEE Symposium on Security and Privacy (IEEE S&P, Oakland) 2021会议接收的学术论文,关于说话人识别系统的黑盒对抗攻击。
前言
IEEE Oakland会议是信息安全四大顶级会议之一(其他三个是ACM CCS, Usenix Security, NDSS),自1980年以来,一直是介绍计算机安全和隐私发展动态的旗舰会议。该会议2010-2019年论文平均接收率为12.6%, 每年大陆学者在Oakland会议上发表论文数量不多。第42届Oakland会议将于2021年5月23日至27日在美国旧金山举办。
论文题目为 Who is Real Bob? Adversarial Attacks on Speaker Recognition Systems,来自上海科技大学 (opens new window) 宋富教授 (opens new window)的S3L (System and Software Security Lab) 课题组 (opens new window)

研究背景
自2013年以来,针对机器学习模型特别是深度神经网络的对抗攻击研究受到了学术界和工业界的广泛关注,相关研究工作数量也井喷式增长。然而,相关工作大多集中在图像以及语音识别领域。说话人识别,即声纹识别,作为一种生物识别技术,应用日益广泛,与此同时其安全性不容忽视。
该论文的主要贡献是首次提出了对说话人识别系统的黑盒对抗攻击,称为FAKEBOB。FAKEBOB在开源和商用声纹识别系统(天聪智能)上均取得接近100%攻击成功率,并且能有效迁移到微软Azure声纹识别系统,包括API攻击以及实际场景下的over-the-air物理攻击。
攻击方法
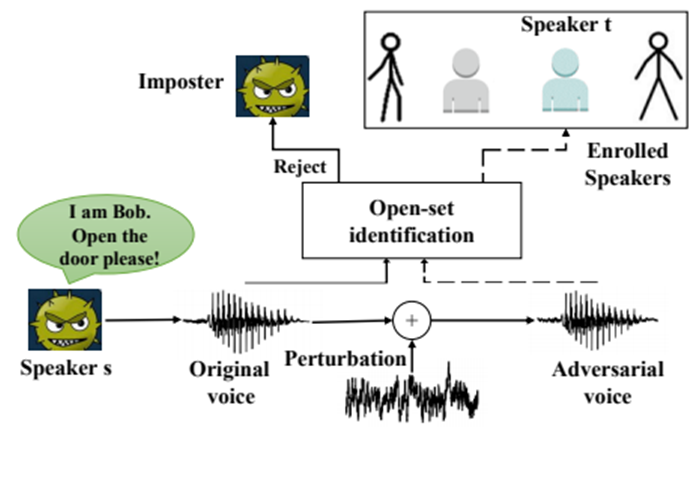
以开集说话人辨认系统 (Open-set Identification, OSI) 为例,FAKEBOB的攻击示意如图2所示,其主要思想是迭代地在一段冒名顶替者的语音上加入人耳无法感知的扰动,生成对抗语音,从而使得系统将对抗语音识别为来自说话人组中的某个(指定的)说话人。基于声纹识别技术的应用场景,攻击者可以利用FAKEBOB进行手机声纹解锁,移动应用声纹登录甚至银行交易声纹验证等,从而对受害者的财产安全,声誉等造成危害。
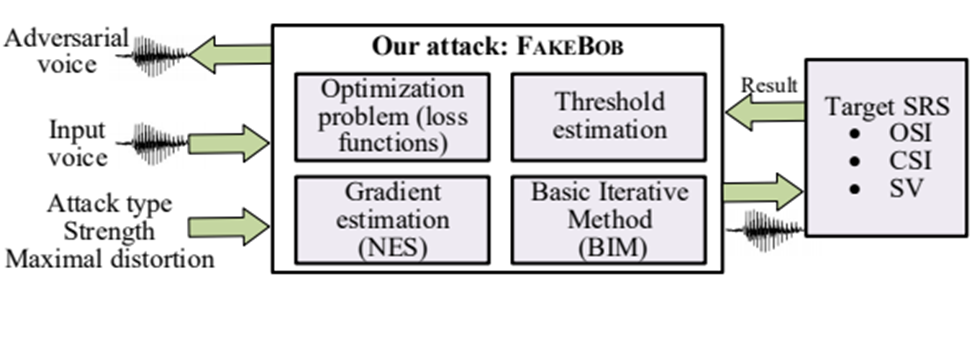
FAKEBOB的框架如图3所示,对抗语音生成被建模为一个带约束 (Maximal distortion) 的优化问题,约束的存在保证添加的扰动不能被人耳感知。FAKEBOB的主要特点包括:
1)对三大不同的说话人识别任务,即开集说话人辨认,闭集说话人辨认 (Close-set Identification, CSI),说话人确认 (Speaker Verification, SV) 均有效。FAKEBOB对不同任务采用了不同的损失函数,以适应不同说话人识别任务打分和决策的差异。
2)和图像识别不同,开集说话人辨认以及说话人确认的决策机制基于一个预设的阈值,只有对抗语音的得分超过阈值,攻击才能成功。但在黑盒攻击模型下,攻击者无法提前获得阈值。为了解决这个问题,该论文提出了阈值估计算法,实验结果显示,该算法能很好地估计实际阈值,即保证估计阈值大于实际阈值但两者差距很小。
3)与白盒攻击不同,FAKEBOB不要求攻击者知道系统的内部结构及参数,数据集等,只需要能够访问受害者的说话人模型(即提供输入语音,获取得分及决策结果)。这一黑盒攻击模型比白盒攻击模型更具现实性。根据调研,多数商用声纹识别系统满足黑盒模型。在黑盒攻击模型下,为了能够利用有效的梯度信息进行梯度下降解决上述优化问题,FAKEBOB使用了基于自然进化策略 (Natural Evolution Strategy, NES) 的梯度估计算法,已有文献显示基于自然进化策略的梯度估计算法比有限差分梯度估计算法更高效。
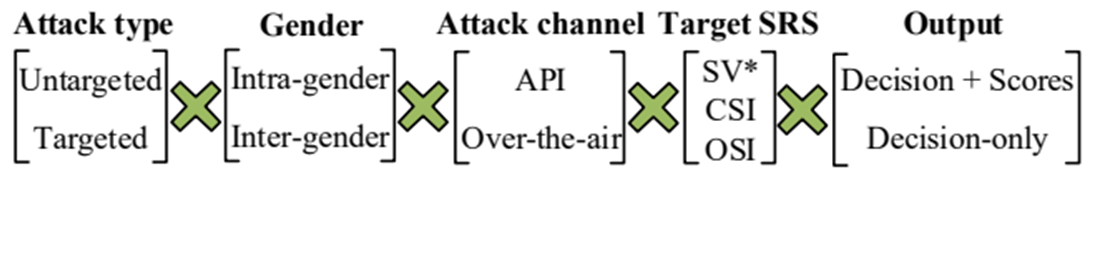
如图4所示,FAKEBOB适用于多种不同的攻击场景
实验结果
1)在Kaldi开源说话人识别系统上,FAKEBOB取得接近100%的攻击成功率。此外FAKEBOB对商用的天聪智能声纹识别系统也取得了100%的攻击成功率,平均API调用次数为2500次。
2)对Decisions-only场景,FAKEBOB采用迁移攻击。实验显示,提高对抗语音的对抗强度 (Strength) 后,在开源系统之间,FAKEBOB最高能取得100%的攻击迁移成功率。此外,FAKEBOB产生的对抗语音能成功迁移到微软商用的Azure开集说话人辨认系统,针对性 (Targeted) 和非针对性 (Untargeted) 攻击迁移率分别达到26%和41%。
3)除了API攻击,FAKEBOB对over-the-air物理攻击同样有效。Over-the-air攻击相比API攻击的难点在于,对抗语音经过扬声器播放,空气信道传播,麦克风接收后,其中的扰动会丢失从而失去对抗性。该论文通过提高对抗语音的对抗强度解决这一问题。实验结果显示这一方案是有效的,对不同的硬件设备(扬声器和麦克风),不同距离(扬声器和麦克风的距离)以及不同声学环境(相对安静,存在高斯白噪声及其他典型生活场景噪声),FAKEBOB都能取得较好的攻击成功率。
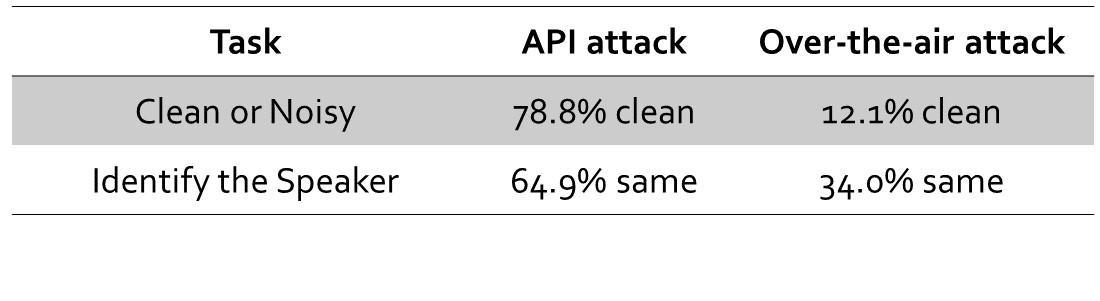
4)为了衡量人耳对加入的扰动的感知度,该论文研究者在亚马逊MTurk平台上进行了两项问卷调查。第一项调查询问参与者是否听到语音中存在噪声,第二项调查询问参与者认为原始语音和对抗语音是否来自同一个说话人。如图5所示,尽管参与者对Over-the-air攻击语音的感知要比API攻击明显,但该结果和已有相似调查具有可比性。第二个调查结果显示,在人耳听起来是来自冒名顶替者的语音却能使得系统错误决策。
5)最后,该论文还验证了FAKEBOB在若干个对抗语音防御或检测方法下的攻击效果。结果显示,对于下采样、中值滤波和比特量化这三种输入变换类的防御方法,通过产生强对抗性语音,FAKEBOB能够逃避这些防御方法,并且这三种方法在增加攻击开销或降低攻击成功率方面效果有限或无效;对于基于时序依赖性的对抗语音检测方法 (Temporal Dependency Detection),由于FAKEBOB并没有改变语音的文本内容,保留了时序依赖性,因此该检测方法接近于随机猜测。
后记
需要注意的是,针对说话人识别的安全威胁还有一类,称为欺骗攻击(Spoofing Attack)。欺骗攻击通过录制或语音合成等方法获取某段语音,该语音人耳听起来像受害者发出,自然地就能被系统识别为来自受害者;而对抗攻击利用的是系统的漏洞,尽管生成的语音人耳听起来根本不像受害者发出,但系统仍然做出错误决策。对抗攻击相比欺骗攻击的优势在于,当有熟悉受害者声音的人(包括受害者自身)在场时,对抗攻击相比欺骗攻击更加隐蔽。
如果你想深入了解这项工作,可以参考以下资料:
FAKEBOB项目主页,需科学上网 (opens new window)
FAKEBOB Github开源代码 (opens new window)
FAKEBOB Gitee开源代码 (opens new window)
最后,欢迎关注 上科大系统与软件安全实验室S3L 微信公众号,更多信息安全方面的前沿动态,等你一起发掘!课题组也持续招收研究生、博后、研究员、实习及访问学生。
