前言
这篇文章分享和介绍我们在声纹识别对抗攻击安全性上的第三项工作(第一项工作介绍参见这篇文章;第二项工作目前还在under review),前段时间被IEEE Transactions on Dependable and Secure Computing (TDSC) 接收,TDSC是计算机安全顶级期刊之一,CCF A类推荐期刊。
论文题目为 AS2T: Arbitrary source-to-target adversarial attack on speaker recognition systems, 来自上海科技大学S3L (System and Software Security Lab) 课题组,本人为第一作者,课题组PI宋富教授为通讯作者,上海科技大学为第一完成单位,具体论文信息如下:

研究背景
自2013年以来,针对深度神经网络的对抗攻击研究受到了学术界和工业界的广泛关注,相关研究工作数量井喷式增长,也从最初的图像分类领域扩展到包括声纹识别在内的其他领域。
声纹识别相比图像分类的差异在于:(1)图像分类是一个闭集的多分类任务,而声纹识别包含开集说话人辨认 (open-set identification, OSI),闭集说话人辨认(close-set identification, CSI)和说话人验证(speaker verification, SV)三种决策机制不同的子任务。(2)声纹识别的输入可以是某个注册人的语音,也可以是假冒者(非注册人)的语音,其决策结果可以是确认输入语音来自某个注册人并指出该注册人(对SV来说,只有一个注册人,对应的决策结果是accept),也可以是认定输入语音来自假冒者,即reject (仅限于OSI和SV)。
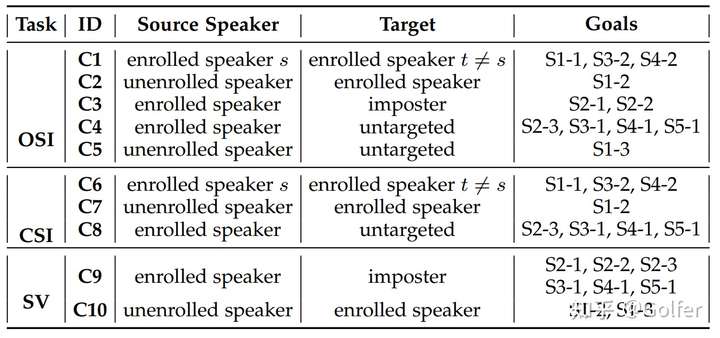
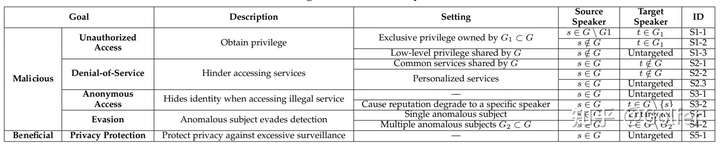
现有的声纹识别对抗攻击研究的局限性在于:只考虑了部分子任务或部分原始以及目标说话人。针对三个子任务上的任意原始以及目标说话人的对抗攻击(见图2,总共有10种不同的设置C1-C10)仍有待且非常值得探究,因为不同的设置往往可以让攻击者实现不同类型的攻击目标(见图3)。这里举两个例子:(1)对语音控制智能家居来说(可看作OSI),部分设备所有家庭成员都有权限控制,但一些设备只有少数成员(如父母)有控制权。对于攻击者来说,其攻击的原始说话人来自非家庭成员(包括攻击者自己),但是目标说话人因攻击目标而异:若想操控后一种类型的设备,需要指定拥有该权限的成员作为目标说话人;若想操控前一种类型的设备,只需要进行难度更低的无目标攻击即可。(2)在SV上(如声纹解锁,app声纹登陆,声纹支付身份验证等),以假冒者为原始说话人,受害者为目标说话人的对抗攻击可以实现非授权访问的目的;而以受害者为原始说话人,假冒者为目标说话人的对抗攻击则可以对受害者进行Denial-of-Service (拒绝服务) 攻击:在受害者说话的时候,播放语音对抗样本,干扰受害者的正常身份验证。
主要贡献
针对该局限性,这项工作提出了适用于任意原始以及目标说话人的声纹识别对抗攻击,称为AS2T。我们工作的主要贡献在于:常用的Cross Entropy Loss以及Margin Loss均无法适用于所有攻击设置,为此我们针对每一种攻击设置,基于经验设计了多种损失函数,并对它们的效果及效率进行了实验比较。由于篇幅限制,这里不加解释地列出这些损失函数,它们的具体含义以及设计的背后动机及原因请参见论文。



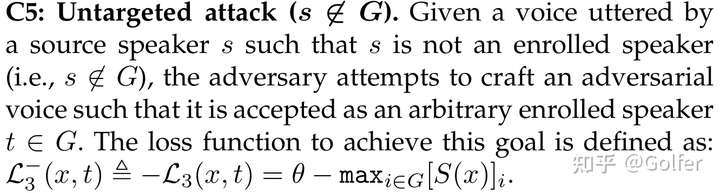




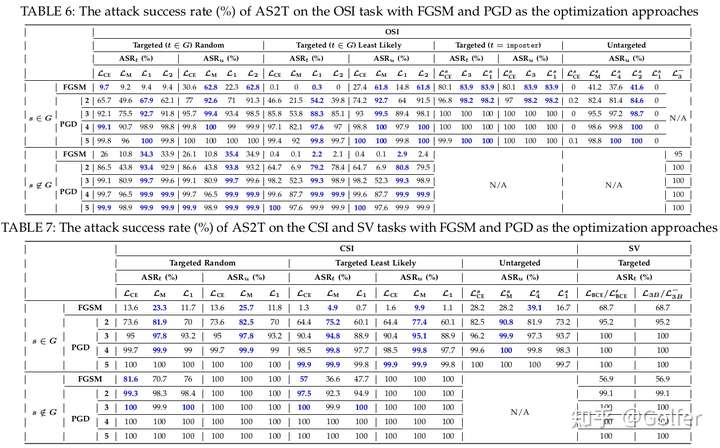
 从不同损失函数的实验结果(见图4)中,我们得到了若干有启发性的发现,如下:
从不同损失函数的实验结果(见图4)中,我们得到了若干有启发性的发现,如下:
当迭代次数较小时,某个损失函数确实比其他损失函数能取得更高的攻击成功率(最好的损失函数在图4中用蓝色标注),且不同攻击设置(C1-C10)的最优损失函数不同,那么我们的研究有利于攻击者根据自己的攻击目的选取攻击设置,进而选取最优的损失函数, 以实现最有效、最高效的攻击。
在OSI上,当目标说话人是其中某个注册人的时候,不管原始说话人是注册人还是假冒者,损失函数的效果排序为: 。Margin Loss 和Cross Entropy Loss 性能差的原因在于它们会同时惩罚目标说话人以及其他注册人的得分(提高前者,降低后者),这样可能会导致目标说话人的得分不能超过OSI的判决阈值(可以想象极端情况,攻击不断降低其他注册人的得分,但不去提高目标说话人的得分,尽管损失函数也下降了),从而攻击失败。相反的是,Margin Loss和Cross Entropy Loss在CSI是能取得最好的效果的,这是OSI和CSI的决策机制差异导致的(CSI判决时不需要最大的得分超越阈值,因此就算只降低其他注册人的得分,攻击也能成功)。类似的是,Margin Loss和Cross Entropy Loss在图像分类被广泛使用,是因为图像分类是一个和CSI一样的闭集多分类任务,这反映了图像识别和声纹识别两个领域的差异性。另一方面,我们之前S&P 2021 FakeBob的工作使用的损失函数是 , 并不是最优的,这项工作是对之前工作的提高和补充。
损失函数 和 适合于OSI上以假冒者为目标说话人的攻击(图4-Table 6的的倒数第二组),但是在OSI上的无目标攻击上表现非常差,攻击成功率几乎为0%(图4-Table 6的最后一组),其原因在于这两个损失函数会试图降低原始说话人的得分,但没有去提高其他说话人的得分,从而得分没法超越阈值,导致攻击失败。
以假冒者为目标说话人的攻击要比以注册人为目标说话人的攻击简单,其原因在于前者只需要关注语音的最大得分与阈值的相对大小,而后者还需要关注目标注册人和其他注册人的得分相对大小;以假冒者为原始说话人的攻击要比以注册人为原始说话人的攻击简单,其原因在于前者的语音初始得分在各个注册人之间比较接近,而后者的语音初始得分会有一个注册人特别高,那么明显改变前者的语音的注册人相对得分大小比后者更简单。
攻击OSI比CSI更难,原因在于OSI上攻击成功需要最大得分超越阈值。
其他贡献
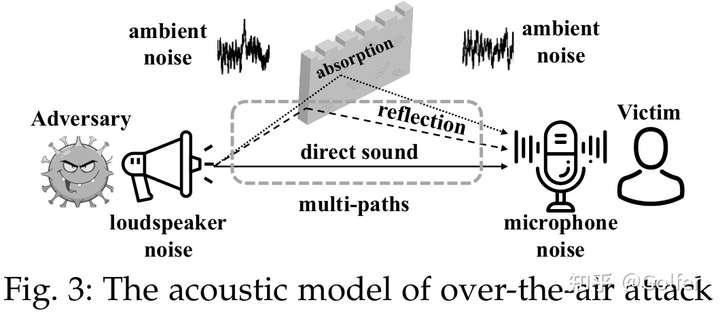
此外,为了让生成的语音对抗样本能在现实播放-录制场景下保持对抗性 (over-the-air攻击),我们分析了over-the-air攻击过程存在的干扰类型(见图5),并针对每种干扰类型设置了不同的参数化的转换函数,并将其集成到对抗样本生成过程中,从而使得对抗样本获取对这些干扰足够的鲁棒性。当然,已有工作也提出过类似方法,我们的不同之处以及贡献主要在于:
我们发现相比混响以及环境噪音,硬件噪声对攻击的影响非常小,不需要专门去处理。
我们的模拟over-the-air实验涵盖的混响(不同室内类型及大小,室内材质的不同的吸收系数及混响时间、硬件之间的不同距离及夹角相对位置)、环境噪音(不同噪声类型、不同噪声SNR以模拟不同的语音对抗样本播放音量)以及硬件设备(不同牌子的扬声器以及麦克风)更全面。全面的场景设置有利于更充分衡量语音对抗样本的鲁棒性,因此我们希望我们对over-the-air的测试方式能成为后续工作的benchmark.
最后,我们使用提出的攻击AS2T,利用14个声纹识别模型,涵盖5种架构(GMM,TDNN,CNN,RNN,Transformer),5个训练集、4种输入类型 (waveform, spectrogram, fbank, mfcc)、2种打分方法 (PLDA, 余弦相似度),进行了目前为止声纹识别上最大规模的迁移攻击实验,分别研究了模型相关的因素和攻击相关的因素(迭代次数、迭代步长、扰动限制大小)对迁移性的影响,得到了若干有启发性的结论,其中有些和图像上的结论不吻合:
多步迭代攻击并不一定比单步攻击迁移差。图像分类的很多文献都强调多步迭代攻击由于对源模型过拟合,迁移性比单步攻击差。
迁移攻击具有不对称性,即模型A到模型B的迁移性好,反方向不一定成立,而且很可能会差非常多,这说明已有的基于模型相似性的迁移攻击解释方法的合理性有待商榷,因为相似性本身是一个对称指标。
相比攻击相关的因素,模型相关的因素是主导因素,对于由于模型相关的因素限制导致迁移性差的攻击,增强攻击相关的因素对提高迁移性作用很有限。
结语
总的来说,这项工作解决了目前声纹识别对抗攻击领域已有研究存在的一个局限性,并且给研究者提供了很多有启发性且有利于未来工作的发现和结论。
如果你想深入了解我们的工作,可以仔细看一下我们在arxiv上的论文;代码后续也会集成到我们第二项工作开发的SpeakerGuard平台(也叫SEC4SR平台,两个平台是一样的,只是名称差异),欢迎star+fork+watch。同时,也欢迎观摩我们已发表在S&P 2021的第一项工作FakeBob (文章前面已多次提及)。
SpeakerGuard平台 (opens new window)